














Why does AI computing use GPU?
The industry usually divides semiconductor chips into digital chips and analog chips. Among them, digital chips account for a relatively large market share, reaching about 70% .
Digital chips can be further subdivided into: logic chips, memory chips and micro control units (MCU).
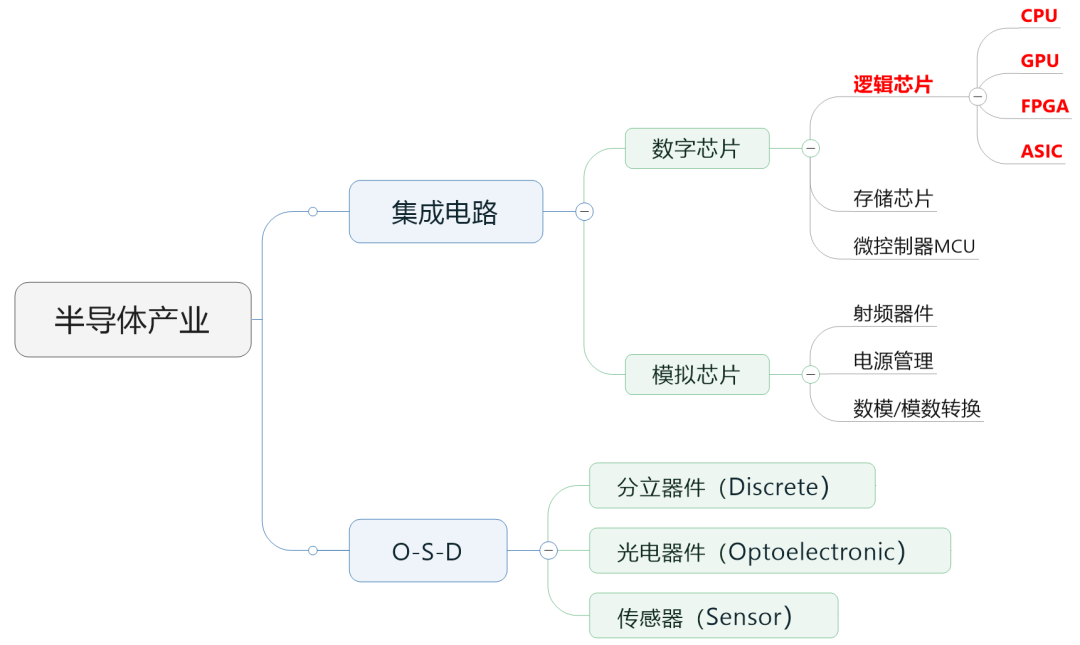
Today we focus on logic chips.
Logic chips are actually computing chips to put it bluntly . It contains various logic gate circuits, which can realize operations and logical judgment functions. It is one of the most common chips.
The CPU, GPU, FPGA, and ASIC that everyone often hears about are all logic chips. And the so-called "AI chips" used in AI, which is particularly popular now, mainly refer to them.
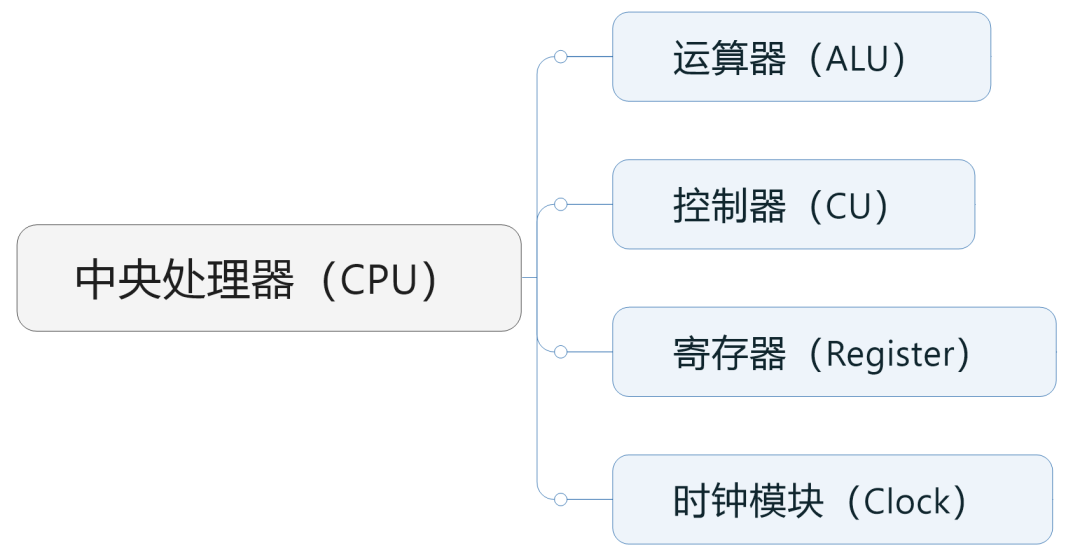
Let’s first talk about the most familiar CPU, the full English name is Central Processing Unit, central processing unit.

Everyone knows that the CPU is the heart of the computer .
Modern computers are all based on the von Neumann architecture born in the 1940s. In this architecture, it includes components such as arithmetic unit (also called logical operation unit, ALU), controller (CU), memory, input device, and output device.
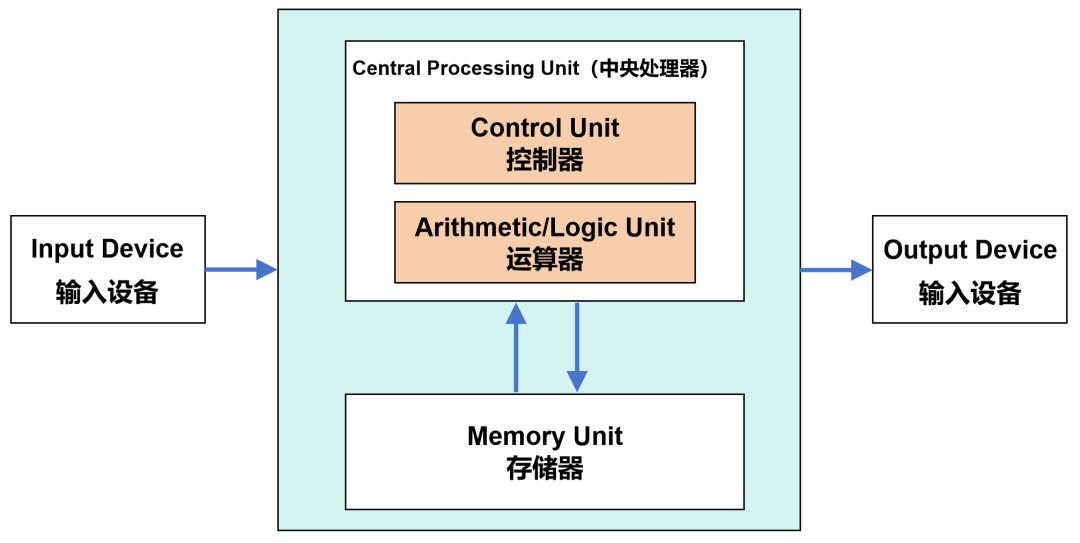
Von Neumann architecture
When the data comes, it will be put into the memory first. Then, the controller will get the corresponding data from the memory and give it to the arithmetic unit for calculation. After the operation is completed, the result is returned to memory .
The two core functions of the arithmetic unit and the controller are both undertaken by the CPU.
Specifically, arithmetic units (including adders, subtractors, multipliers, and dividers) are responsible for performing arithmetic and logical operations and are the real work. The controller is responsible for reading instructions from memory, decoding instructions, and executing instructions.
In addition to arithmetic units and controllers, CPUs also include components such as clock modules and registers (cache).
Let’s take a look at the GPU.
GPU is the core component of the graphics card. Its full English name is Graphics Processing Unit, graphics processing unit (graphics processor).
GPU cannot be equated with graphics card . In addition to the GPU, the graphics card also includes video memory, VRM voltage stabilizing module, MRAM chip, bus, fan, peripheral device interface, etc.

In 1999, NVIDIA took the lead in proposing the concept of GPU
The reason why GPU is proposed is because the game and multimedia business developed rapidly in the 1990s. These businesses put forward higher requirements for the computer's 3D graphics processing and rendering capabilities. Traditional CPUs couldn't handle it, so GPUs were introduced to share the work.
GPUs are also computing chips. Therefore, like the CPU, it includes components such as arithmetic units, controllers, and registers .
However, because the GPU is mainly responsible for graphics processing tasks, its internal architecture is very different from that of the CPU .
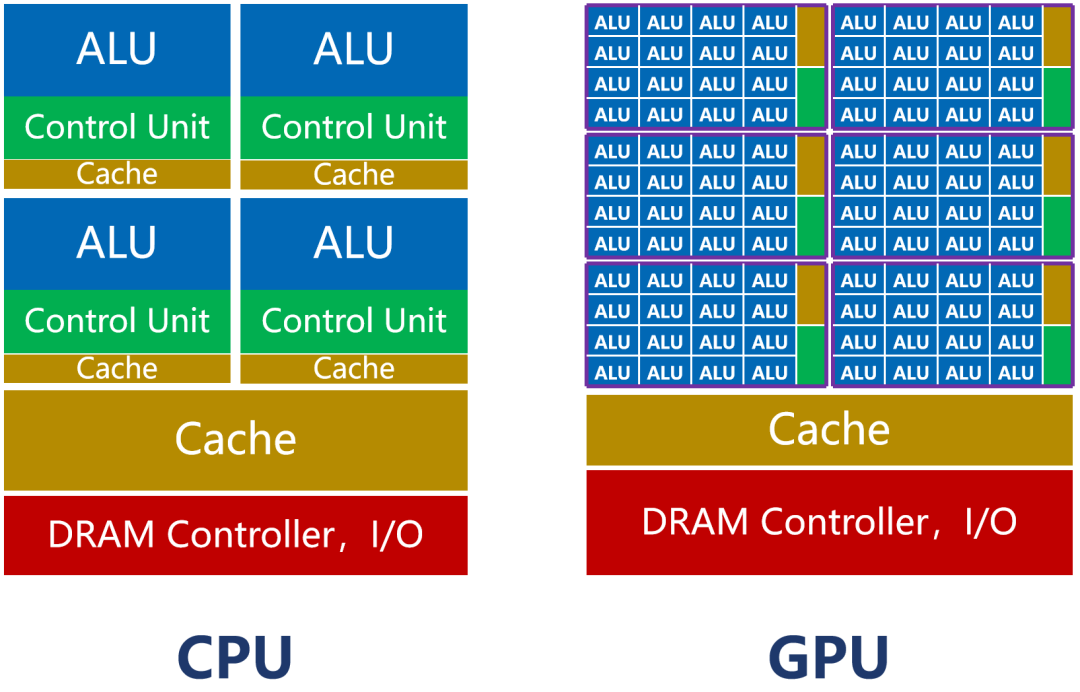
As shown in the figure above, the number of CPU cores (including ALU) is relatively small, only a few dozen at most . However, the CPU has a large cache (Cache) and a complex controller (CU) .
The reason for this design is because the CPU is a general-purpose processor. As the main core of the computer, its tasks are very complex. It must deal with different types of data calculations and respond to human-computer interaction .
Complex conditions and branches, as well as synchronization and coordination between tasks, will bring a lot of branch jumps and interrupt processing work. It requires a larger cache to save various task states to reduce the delay during task switching. It also requires more complex controllers for logic control and scheduling.
The strength of the CPU is management and scheduling. The real work function is not strong (ALU accounts for about 5 %~20%).
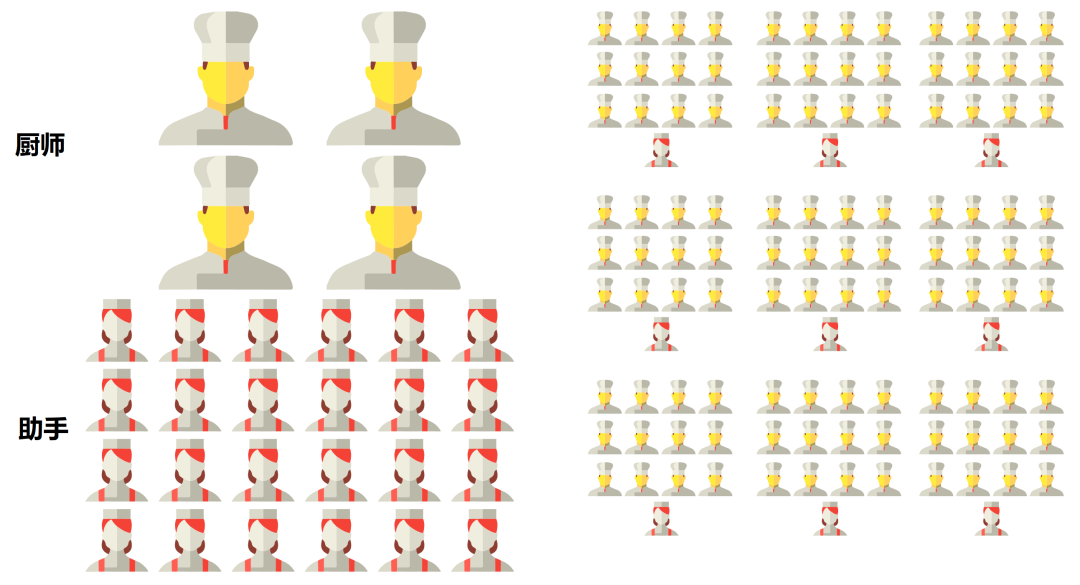
If we think of the processor as a restaurant, the CPU is like an all-round restaurant with dozens of senior chefs. This restaurant can cook all kinds of cuisines, but because there are so many cuisines, it takes a lot of time to coordinate and prepare the dishes, and the serving speed is relatively slow.
The GPU is completely different.
GPUs are designed for graphics processing, and their tasks are very clear and single . What it does is graphics rendering. Graphics are composed of massive pixels, which are large-scale data with highly unified types and no dependence on each other.
Therefore, the task of the GPU is to complete parallel operations on a large amount of homogeneous data in the shortest possible time. The so-called "chores" of scheduling and coordination are actually very few.
Parallel computing, of course, requires more cores.
As shown in the previous figure, the number of cores of the GPU far exceeds that of the CPU , and can reach thousands or even tens of thousands (so it is called "many-core").

RTX4090 has 16384 stream processors
The core of the GPU, called the Stream Multi-processor (SM), is an independent task processing unit.
The entire GPU is divided into multiple streaming processing areas. Each processing area,contains hundreds of cores. Each core is equivalent to a simplified version of the CPU, with the functions of integer operations and floating point operations, as well as queuing and result collection functions.
The GPU controller has simple functions and relatively few caches. Its ALU ratio can reach more than 80%.
Although the processing power of a single GPU core is weaker than that of a CPU, its large number makes it very suitable for high-intensity parallel computing. Under the same transistor scale, its computing power is stronger than that of the CPU.
Let’s take the restaurant as an example. A GPU is like a monolithic restaurant with thousands of junior chefs. It is only suitable for certain cuisines. However, because there are many chefs and the side dishes are simple, everyone cooks together and the food is served faster.
CPU vs GPU
As we all know, everyone is rushing to buy GPUs for AI computing now. Nvidia also made a lot of money from this. Why is this so?
The reason is simple, because AI computing, like graphics computing, also contains a large number of high-intensity parallel computing tasks.
Deep learning is currently the most mainstream artificial intelligence algorithm. From a process perspective, it includes two links: training and inference.
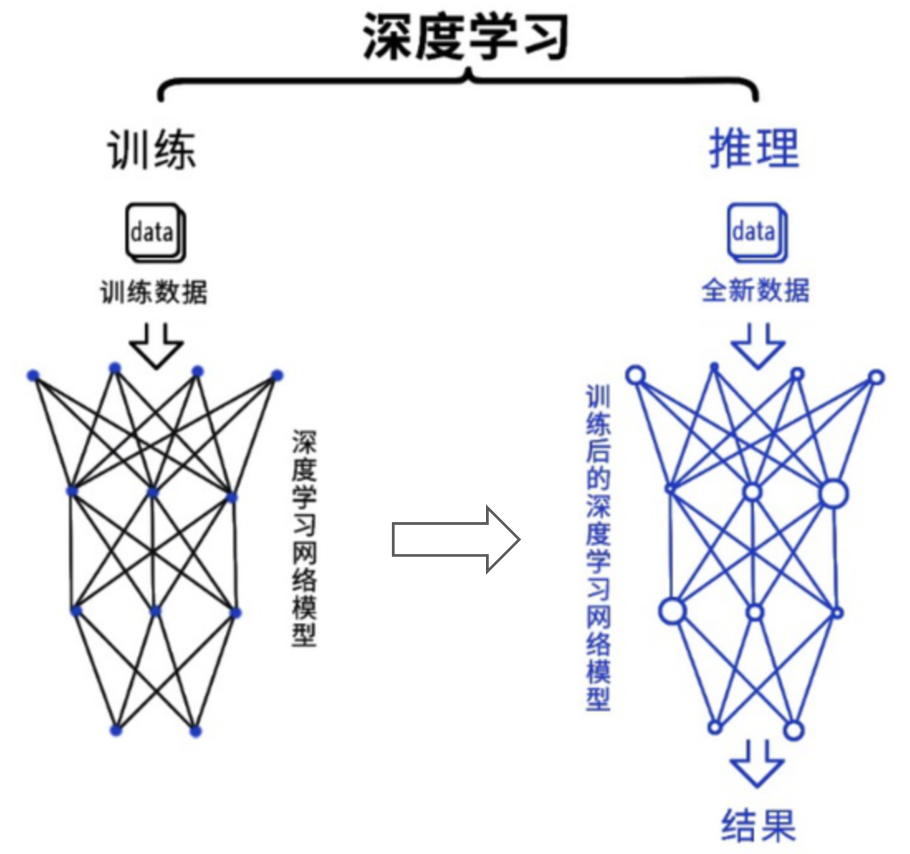
In the training process, a complex neural network model is trained by feeding a large amount of data. In the reasoning process, the trained model is used to infer various conclusions using a large amount of data.
Since the training process involves massive training data and complex deep neural network structures, it requires a very large scale of calculation and requires relatively high computing power performance of the chip. The reasoning process has high requirements for simple specified repeated calculations and low latency.
The specific algorithms they use, including matrix multiplication, convolution, loop layer, gradient operation, etc., are decomposed into a large number of parallel tasks, which can effectively shorten the time for task completion.
With its powerful parallel computing capabilities and memory bandwidth, GPU can handle training and inference tasks well, and has become the industry's preferred solution in the field of deep learning.
Currently, most companies use NVIDIA GPU clusters for AI training. If properly optimized, a GPU card can provide the computing power equivalent to dozens to hundreds of CPU servers .

NVIDIA HGX A100 8 GPU components
However, in the inference segment, the market share of GPU is not that high.
In AI reasoning, the input is generally a single object (image), so the requirements are lower, and there is no need for parallelism, so the computing power advantage of the GPU is not that obvious. Many companies will begin to use cheaper and more power-saving CPUs or FPGAs and ASICs for calculations.
Applying GPU to calculations other than graphics first originated in 2003.
That year, the concept of GPGPU (General Purpose computing on GPU, GPU-based general computing) was first proposed. It means using the computing power of GPU to perform more general and extensive scientific calculations in non-graphics processing fields.
On the basis of traditional GPU, GPGPU has been further optimized and designed to make it more suitable for high-performance parallel computing.
In 2009, several Stanford scholars demonstrated for the first time the results of using GPUs to train deep neural networks, which caused a sensation.
A few years later, in 2012, two students of Geoffrey Hinton, the father of neural networks, Alex Krizhevsky and Ilya Sutskvo (Ilya Sutskever), using the "deep learning + GPU" solution, proposed the deep neural network AlexNet, which increased the recognition success rate from 74% to 85%, winning the Image Net Challenge in one fell swoop.

Ilya Sutskvo/Alex Krichevsky/Jeffrey Hinton
This completely detonated the "AI+GPU" wave. Nvidia quickly followed up and invested a lot of resources, improving GPU performance by 65 times in three years.
In addition to hard-core computing power, they are also actively building a development ecosystem around GPUs. They have established a CUDA (Compute Unified Device Architecture) ecosystem based on their own GPUs, providing a complete development environment and solutions to help developers more easily use GPUs for deep learning development or high-performance computing.
These early careful layouts ultimately helped Nvidia reap huge dividends when AIGC broke out. Currently, their market value is as high as US$1.22 trillion (nearly 6 times that of Intel), making them the veritable “uncrowned king of AI.”


.png)
